Essential Concepts of Distributed System Design
Having explored distributed systems and system design during my GovTech internship, here are some essential concepts I’ve learned.
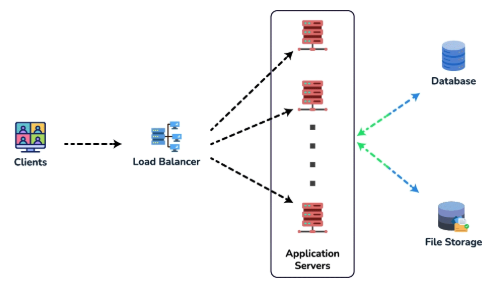
Scalability
- Vertical Scaling: Increase resources (CPU, RAM) on a single server. Simple but limited by hardware constraints.
- Horizontal Scaling: Add more servers to distribute the load. Offers fault tolerance and better resilience.
Proxy vs Reverse Proxy
- Forward Proxy: Sits between clients and servers. Hides client identity, enables caching, and content filtering.
- Reverse Proxy: Sits in front of servers. Handles load balancing, anonymity, and caching. Often used to protect backend servers.
Load Balancer
- Usually acts as a reverse proxy.
- Ensures fault tolerance and distributes traffic using algorithms like round-robin, IP hashing, or least active connections.
- Performs health checks to route traffic only to healthy servers.
- Often includes a secondary load balancer for redundancy.
API Gateway
- Acts as a reverse proxy, usually placed after a load balancer.
- Handles API transformation (data type or protocol conversion), request routing, rate limiting, authentication, and authorization.
- Provides a single entry point for multiple microservices, making it easier to scale and manage.
Caching
- Types: In-memory (Redis, Memcached), disk, DB, client-side, server-side, CDN, DNS.
- Write Strategies: Write-through (write to cache and DB simultaneously), write-around (write directly to DB), write-back (write to cache first, then DB later).
- Read Strategies: Read-through (cache fetches data if missing), read-aside (application fetches data and updates cache).
- Cache Eviction: LRU (Least Recently Used), LFU (Least Frequently Used).
Data Partitioning
- Horizontal Partitioning (Sharding): Splits data across multiple servers based on a key (e.g., user ID).
- Vertical Partitioning: Splits tables by columns, storing different attributes on different servers.
- Issues: Joins become harder (denormalization required), referential integrity (foreign keys across servers), and rebalancing (changing partition schemes).
Replication
- Synchronous: Data is replicated in real-time across nodes. Ensures consistency but can be slower.
- Asynchronous: Data is replicated with a delay. Faster but can lead to temporary inconsistencies.
- Master-Slave: Only the master node can write; slaves replicate data for read scalability.
- Master-Master: Multiple nodes can write, but conflict resolution is complex.
SQL vs NoSQL
- SQL: ACID-compliant, ideal for structured data. Built-in vertical scaling but harder to scale horizontally due to complex joins and relationships.
- NoSQL: Flexible schema, better for horizontal scaling. Follows BASE (Basically Available, Soft state, Eventual consistency) principles. Faster writes due to no transaction locks.
CAP Theorem
- Consistency: All nodes see the latest write.
- Availability: Every request gets a response, even if some nodes fail.
- Partition Tolerance: The system continues to operate despite communication failures between nodes.
Latency & Throughput
- Latency: The delay between a request and response. Improve using CDNs, caching, hardware upgrades, indexing, and load balancing.
- Throughput: The amount of work done per unit time. Improve by horizontal scaling, caching, parallel/batch processing, and increasing network bandwidth.
Batch vs Stream Processing
- Batch Processing: Processes data in batches. Ideal for non-real-time tasks like analytics.
- Stream Processing: Processes data in real-time. More complex and resource-intensive but essential for real-time applications.
Data Compression vs Deduplication
- Compression: Reduces data size by encoding it with fewer bits.
- Deduplication: Eliminates duplicate data, saving storage space.
REST vs GraphQL vs RPC
- REST: Uses multiple endpoints, simple to implement, and works well with HTTP caching (e.g., CDNs).
- GraphQL: Uses a single endpoint, offers flexible schema, and allows query-level caching. Easier to version APIs.
- RPC: Uses function calls instead of endpoints, enabling low-latency communication. Efficient for microservices but may require strict contracts and serialization formats (e.g., Protobuf for gRPC).
Polling vs Long Polling vs WebSockets vs SSE
- Polling: Periodic requests; connection closes after response.
- Long Polling: Persistent connection until a response is received.
- WebSockets: Bi-directional, full-duplex communication. Requires sticky sessions for scaling.
- SSE: One-way communication from server to client. Persistent until closed. Usually does not need sticky sessions.
CDN
- Distributed servers based on geographical location to deliver content faster.
Serverless
- Cloud providers dynamically manage server allocation. Scales automatically based on demand.
- Serverless functions are typically stateless, making them ideal for event-driven architectures.
Designing for Read-Heavy Systems
- Use in-memory caching (e.g., Redis) to reduce database load.
- Replicate databases to distribute read traffic.
- Use CDNs to serve content closer to users.
- Implement horizontal sharding based on geographical location.
- Use asynchronous processing for non-real-time tasks.
Designing for Write-Heavy Systems
- Use databases optimized for high writes (e.g., NoSQL like MongoDB).
- Batch multiple write requests to reduce the number of operations.
- Handle write processes asynchronously in the background.
- Use data partitioning and Write-Ahead Logging (WAL) for durability.