C++ Custom Implementations

In this C++ Internals Blog, I am documenting my custom implementations of essential C++ components, including a hashmap, thread‑safe singly linked list, thread‑safe queue, string class with small string optimization, vector, shared pointer, and unique pointer. Each implementation has a robust slew of test cases using the gtest framework.
Github LinkFor each of these components, I discuss my design decisions, what I learned along the way, potential future improvements, and how they relate to critical low‑latency performance considerations. In particular, I explore how CPU cache lines and memory locality, out‑of‑order (OoO) processing, and CPU branch prediction can affect the performance of these data structures.
Understanding Cache Lines, Memory Locality, Alignment, and False Sharing
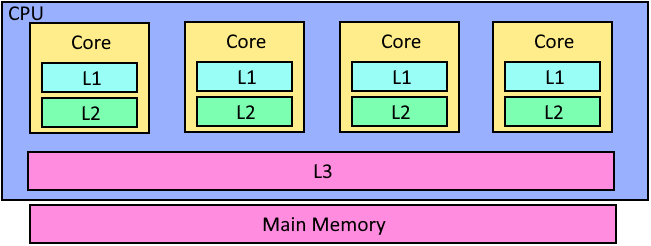
Cache Lines and Memory Locality
Modern CPUs have multiple levels of cache (L1, L2, and L3), each operating on fixed-size blocks of memory known as cache lines. Typically, a cache line is 64 bytes. When data is stored contiguously (for example, in a vector), accessing one element usually loads the entire cache line into the cache. This means that if you access the first element of a vector of integers, several subsequent elements are also loaded into the cache. As a result, even if you haven’t directly accessed the second element, it is already available in the cache—a phenomenon known as spatial locality.
In contrast, a cache miss—when the required data is not in the cache—forces the CPU to retrieve data from main memory, which is orders of magnitude slower than cache access. Therefore, spatial locality is a good way to increase the cache hit rate.
Cache Alignment
Cache alignment involves organizing data so that its starting address falls on a boundary that matches the size of
a cache line (commonly 64 bytes). In C++, you can enforce this by using the alignas(64) specifier. When
data structures are aligned on cache line boundaries, a single memory fetch can pull in a complete, useful block of
data, reducing the need for multiple, slower fetches if the data were split across cache lines.
Starting on a cache line boundary improves cache hits because it minimizes the possibility of data straddling two cache lines. This ensures that when a cache line is loaded, all of the data you expect to access together is available in one go.
False Sharing
False sharing occurs in multi-threaded environments when independent data items, frequently updated by different threads, reside on the same cache line. Even though the data are unrelated, an update to one piece of data can trigger the invalidation of the entire cache line. Consequently, other threads must fetch the updated cache line, incurring extra latency.
To mitigate false sharing, you can pad data structures or use alignment strategies (such as alignas)
to ensure that frequently updated variables are placed in separate cache lines. This prevents the cache coherence
mechanism from causing unnecessary slowdowns due to cache line invalidation.
Out‑of‑Order Execution
Modern CPUs use out‑of‑order (OoO) execution to maximize the utilization of their internal execution units. Instead of strictly following the program order, the CPU reorders instructions at runtime to keep its pipelines busy. It executes instructions as soon as their operands become available rather than waiting for earlier instructions to finish.
How It Works
- Instruction Scheduling: The CPU's scheduler collects instructions from a window of pending operations and dynamically determines the optimal order for executing them. This decision is based on data dependencies and resource availability, allowing independent instructions to execute in parallel.
- Reservation Stations & Reorder Buffers: Instructions waiting for operands are placed in reservation stations where they wait until all required data is ready. Once executed, their results are stored in a reorder buffer. The CPU then commits the results in the original program order, ensuring correct semantics.
Impact on Latency
Out‑of‑order execution can significantly improve latency by allowing the CPU to hide memory and execution delays. When independent instructions are executed concurrently, the CPU avoids idling its execution units, effectively increasing throughput.
When OoO Execution Is Limited
- Dependency Stalls: If an instruction depends on the result of a previous operation, it must wait until that operation completes. Such stalls limit the benefits of OoO execution since the dependent instruction cannot be re‐ordered.
- Resource Contention: When multiple instructions compete for the same functional units (such as ALUs or load/store units), resource saturation can occur. In critical loops, if key operations experience delays, the overall throughput suffers, diminishing the gains from out‑of‑order execution.
Branch Prediction?
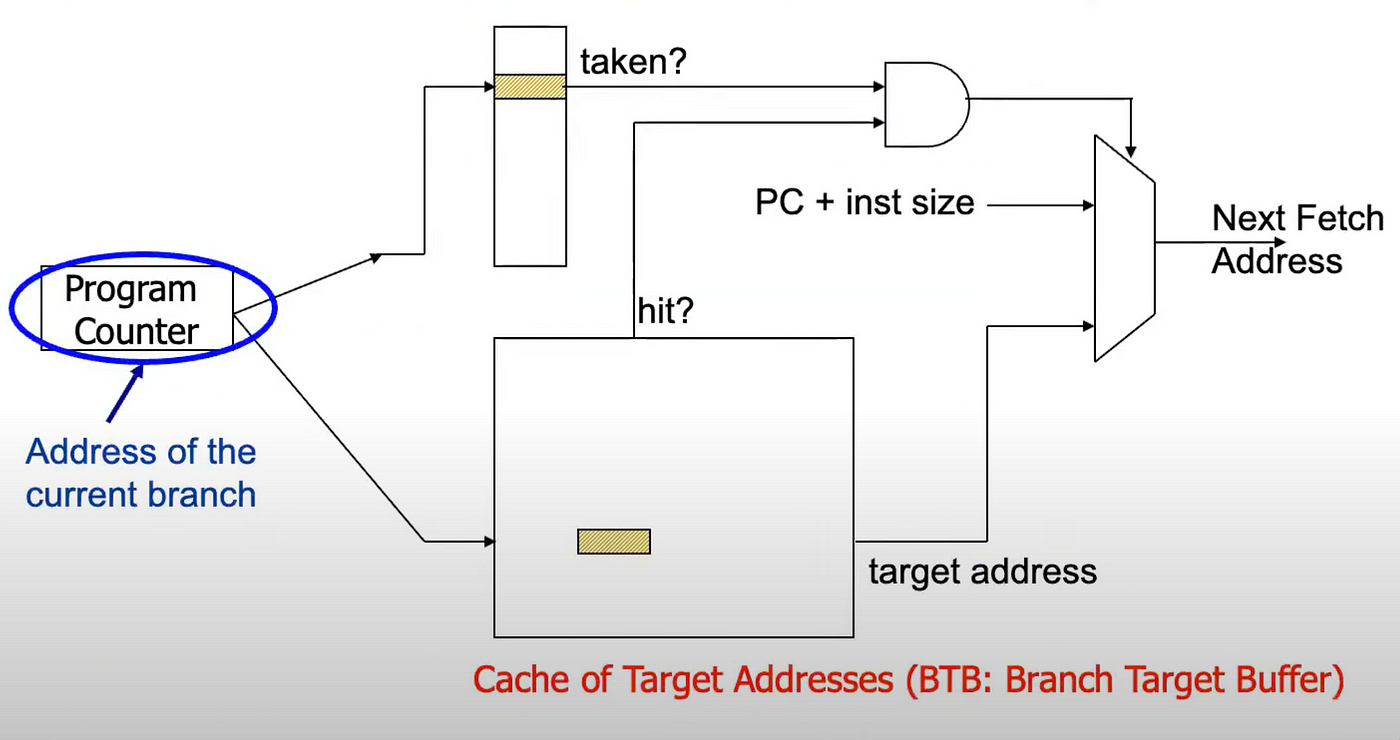
Branch prediction is a technique used by modern CPUs to guess the outcome of a conditional branch (such as an if statement or loop exit) before it is definitively known. By doing so, the CPU can keep its instruction pipeline full,
minimizing stalls that occur when the correct execution path is not immediately clear.
How It Works
- Prediction Algorithms: CPUs typically use algorithms (such as a two‑bit predictor or more advanced neural predictors in modern processors) to forecast whether a branch will be taken or not, based on past behavior. These algorithms analyze historical outcomes, allowing the CPU to learn patterns and make accurate predictions most of the time.
- Speculative Execution: Once a branch is predicted, the CPU speculatively executes subsequent instructions along the predicted path. If the prediction is correct, the results of the speculative execution are committed, and the execution proceeds without interruption. If the prediction turns out to be wrong, the CPU discards the speculated results and restarts execution at the correct branch target.
How Branch Prediction Reduces Latency
By guessing the outcome of conditional branches in advance, branch prediction keeps the CPU's pipeline busy. This means that while the actual branch decision is being determined, the CPU is already executing the predicted instructions. If the prediction is correct, this process avoids the latency that would otherwise occur from waiting for the branch decision and refilling the pipeline with the correct instructions. In essence, effective branch prediction minimizes idle cycles and maximizes instruction throughput.
When Can Branch Prediction Cause More Latency?
- The speculative instructions executed along the wrong path are discarded, and the instruction pipeline must be flushed. This flushing process introduces delays, as the correct path must then be fetched, decoded, and executed.
- Frequent mispredictions, which can occur in code with irregular control flow or data-dependent conditions that are hard to predict, can lead to significant performance penalties.
Programmers can assist the compiler in branch prediction by using attributes like likely and unlikely or using
compiler built‑in functions like __builtin_expect to guide the prediction of conditions.
Template‑Based, Header‑Only Design & Rule of Five Compliance
In my custom C++ implementations (except for the string class), I leverage templates so that each component (such
as unique_ptr, shared_ptr, vectors, thread‑safe containers, etc.) can handle any type.
By defining these classes as templates, I place the entire implementation in header files. This approach is
standard in C++ because the template code is instantiated only when included in a translation unit.
This design offers several advantages:
- Maximizes Inlining: Since all the definitions are available in headers, the compiler is free to inline functions wherever it deems appropriate. Inlining helps reduce the overhead of function calls, especially in performance‑sensitive applications.
- Ensures Type Safety: With templates, the compiler generates tailored code for each specific type. This means that type errors are caught at compile‑time, and the generated code is optimized for the particular type being used.
Another cornerstone of my design is adherence to the Rule of Five:
- Constructor(s): Sometimes marked as explicit to avoid implicit type conversion.
- Destructor:
The destructor is implemented to correctly release resources (for example, calling
deleteon the managed object). - Move Constructor and Move Assignment Operator:
Both are marked
noexceptto signal that they are guaranteed not to throw. This enables standard containers to employ move semantics safely during resizing or other operations without falling back to less efficient copying. - Copy Constructor and Copy Assignment Operator: In many of my implementations, these are either implemented carefully or deleted altogether to enforce unique ownership or non‑copyable semantics—ensuring that resource management remains robust.
Overall, the template‑based, header‑only design not only simplifies the code generation process and ensures type safety but also creates ample opportunities for compiler optimizations that are key for high‑performance, low‑latency systems.
Table of Contents
Unique Pointer
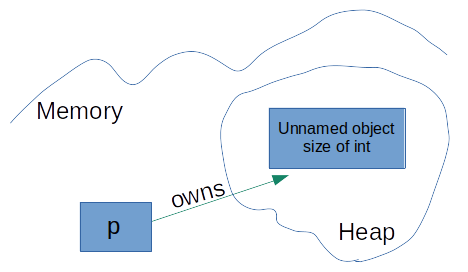
My custom UniquePtr is designed around a simple yet powerful concept: a raw pointer that cleans up after itself once the smart pointer goes out of scope. This automatic resource cleanup is a cornerstone of RAII (Resource Acquisition Is Initialization) in C++, ensuring that resources are properly deallocated without explicit intervention.
Destructor
The destructor of UniquePtr is straightforward. It calls delete on the managed pointer, ensuring
that the underlying object is destroyed when the UniquePtr goes out of scope:
Explicit Constructor
The constructor that takes a raw pointer is declared with the explicit keyword:
This is crucial because it prevents implicit conversions from a raw pointer to a UniquePtr. Without explicit, a function expecting a
UniquePtr might accidentally receive a raw pointer, leading the compiler to automatically create a temporary
UniquePtr. Such implicit conversions can result in unexpected behavior or resource management issues.
Deleted Copy Constructor and Copy Assignment Operator
To enforce unique ownership, copying is disabled by deleting the copy constructor and copy assignment operator
With these functions deleted, only one instance of UniquePtr can own a given pointer, preventing issues
like double deletion.
Low-Level Performance Considerations
In terms of memory, a raw pointer typically occupies 4 or 8 bytes (depending on the architecture), which is a very small footprint that easily fits within a single cache line. This compact size helps keep cache usage minimal and ensures that access to the pointer is extremely fast.
Branch Prediction in Move Assignment
In the move assignment operator, I include a conditional check to guard against self-assignment
Although this if (this != &other) introduces a branch, modern CPU branch predictors are highly efficient
at handling such simple conditions. Additionally, self-assignment via move is a very rare occurrence, so the predictor
almost always guesses correctly and the latency overhead is negligible.
Shared Pointer
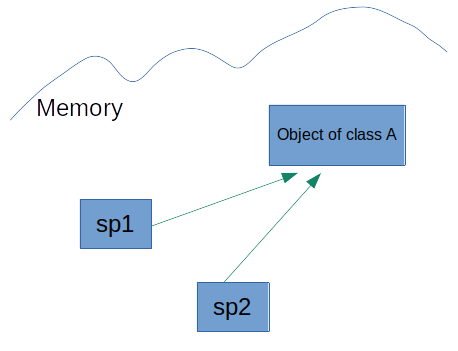
Unlike UniquePtr, my custom SharedPtr allows multiple instances to own the same object. This
shared ownership is built on top of the RAII principles that govern UniquePtr, with the addition of a
reference counter.
The reference counter is stored as an atomic variable: std::atomic
Using std::atomic ensures thread safety because most atomic operations compile down to a single assembly
instruction, minimizing interleaving between threads and preventing race conditions. While I could have guarded the
reference counter with a mutex, that approach would introduce lock contention and additional overhead, so an atomic
variable is a more efficient solution.
Why size_t?
The counter uses size_t because this unsigned integer type is designed to represent sizes and
counts. Although on many platforms int and size_t might both be 4 bytes, using size_t avoids negative values and semantically indicates a count or size, which is appropriate for reference counting.
The behavior of the SharedPtr is as follows:
- On Copy: Copying a shared pointer increases the reference count, reflecting the additional owner.
- Destructor: When a
SharedPtris destroyed, it decrements the reference count. If the reference count reaches zero, the raw pointer is deleted—ensuring that the managed object is freed only when no shared pointer is referencing it.
An interesting detail of STL’s std::shared_ptr is its additional weak reference count. A weak pointer
does not contribute to the reference count. Initially, I was puzzled by the purpose of a weak reference count. If
code attempts to convert a weak pointer to a shared pointer, the weak reference count helps ensure that the conversion
fails gracefully when the managed object has already been destroyed— avoiding access to invalid memory and preventing
potential segmentation faults.
Cache Coherency and Performance Considerations:
When a thread increments or decrements the atomic counter, the corresponding cache line is updated and potentially
invalidated across cores. While this does introduce some overhead through the cache coherence mechanism, shared pointers
are generally less prone to false sharing compared to other highly mutable data structures—since reference count
modifications occur relatively infrequently.
Vector
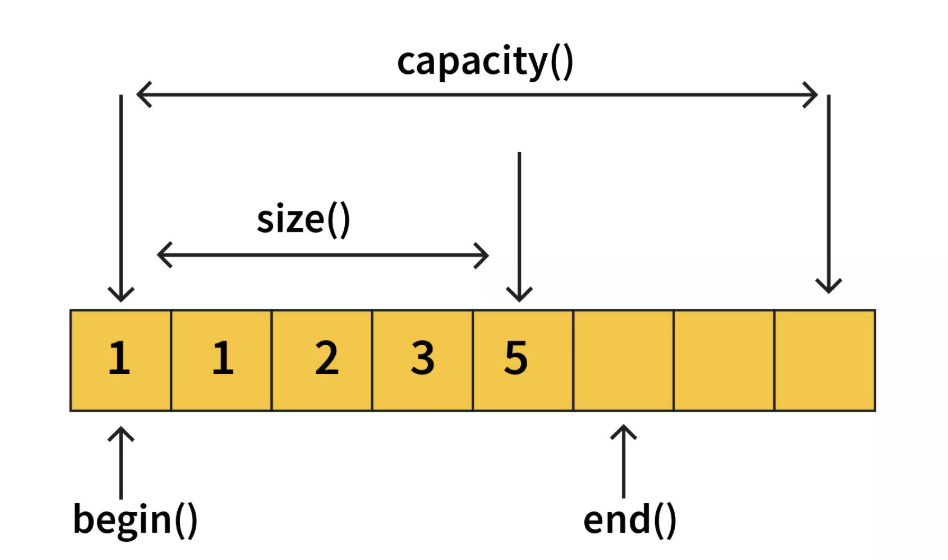
My custom Vector is built around a few essential private members:
-
T* ptr: A raw pointer to the beginning of the allocated memory block. This raw pointer provides full flexibility over when and how memory is allocated and deallocated. -
size_t m_capacity: The total allocated capacity, used to ensure there’s space available for new elements. size_t idx: A counter tracking how many elements are currently stored in the vector.
The Vector class is implemented as a template and is entirely header‑only, ensuring that the compiler
generates type‑specific code and maximizing the possibility for inlining. This design is especially useful in performance‑sensitive
environments.
Construction, Copying, and Moving
The default constructor sets ptr to nullptr and initializes both m_capacity and idx to zero. The copy constructor allocates sufficient memory and uses placement new to copy each
element. The move constructor transfers ownership of the pointer, resetting the source vector to a safe empty state.
The std::move assume noexcept move constructors. If a move throws, the vector is left in an invalid state.
To simplify exception safety and memory management, both the copy and move assignment operators follow the “copy‑and‑swap” idiom. A temporary vector is constructed from the source (by copying or moving), and then swapped with the current instance. This design minimizes explicit reallocation logic while allowing the temporary object to handle cleanup when it goes out of scope.
Insertion: push_back() and emplace_back()
When inserting a new element, if the vector is full, the resize() function is invoked to double the
capacity (or allocate one unit if the vector is initially empty).
- push_back() copies the provided object into the vector.
- emplace_back() constructs the new object in-place using perfect forwarding. This approach avoids unnecessary copies by forwarding rvalue arguments directly to the constructor, which is crucial in performance‑sensitive code.
Resizing Mechanism
The resize() function does the heavy lifting for growing the vector:
-
Memory is allocated using
::operator new—which allocates a raw memory block without invoking constructors. -
Existing elements are moved into the new memory block using placement new with
std::move, capitalizing on move semantics to reduce overhead. -
Destructors for the old elements are explicitly called, and the old memory is freed using
::operator delete.
Low‑Level Performance Considerations
Cache Locality: A key benefit of a vector’s contiguous memory layout is excellent cache locality. When iterating over elements, the CPU prefetches adjacent data—if the first index of an integer vector is accessed, the adjacent elements are loaded into cache as well. This minimizes cache misses, which is especially critical in low‑latency systems like high‑frequency trading.
Thread Safety (Future Consideration): This vector is currently not thread‑safe. If you were to add locks to make it thread‑safe, you could face challenges:
- Coarse‑grained Locking: Locking the entire vector would serialize access, potentially reducing parallelism and increasing lock contention.
- Fine‑grained Locking: Locking each index could lead to false sharing if the lock objects are stored contiguously—multiple locks sharing the same cache line would incur extra latency due to cache coherence overhead.
Out‑of‑Order Execution:
In the inner loops of functions like resize(), where elements are moved or constructed in a new
memory block, instructions that are independent of each other can be executed out‑of‑order by the CPU. This
helps to hide memory latency and improve throughput, provided that there are few dependencies between the
operations.
Branch Prediction:
Simple conditionals, such as checking if an index is within bounds in operator[] or determining if the
vector is full in push_back(), are highly predictable in typical use cases. Modern CPUs efficiently
predict these branches, so their cost is minimal. When branches are well‑predicted, the instruction pipeline
remains full, further reducing latency.
Overall, my custom vector implementation focuses on efficiency and robustness, leveraging raw pointer flexibility and modern C++ features like move semantics and perfect forwarding. At the same time, I consider the interplay of data structure design with underlying hardware aspects to ensure that even the smallest inefficiencies are minimized.
Thread Safe Queue
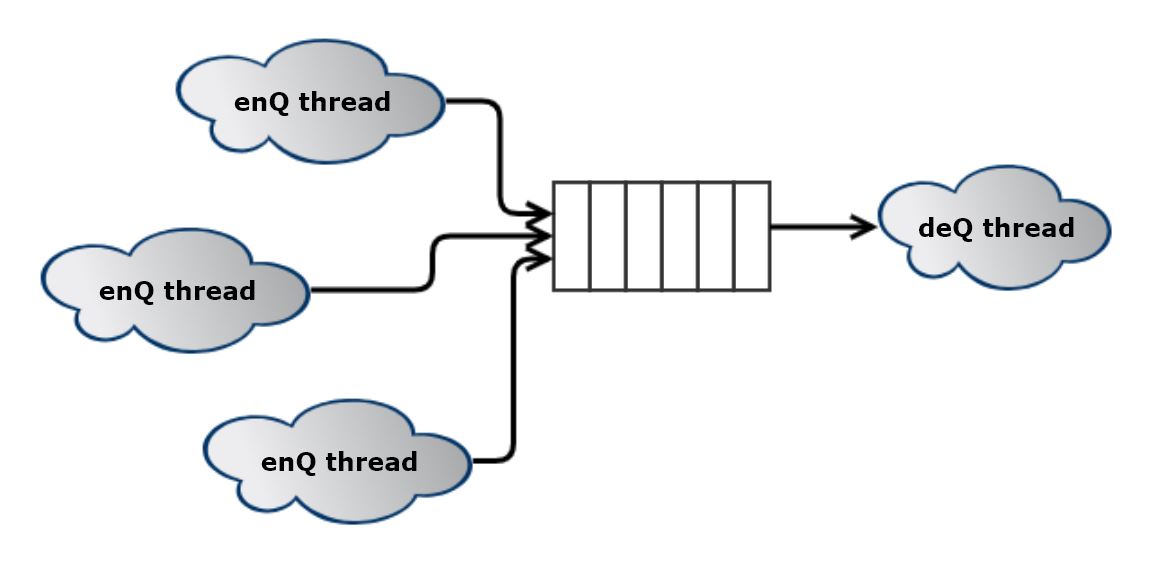
In my Thread Safe Queue, I wrap a standard std::queue with a coarse‑grained lock and a condition variable
to ensure thread safety. A single mutable std::mutex protects the entire queue, while the condition
variable (std::condition_variable) is used to signal waiting threads when new data becomes
available. Using mutable here allows even const member functions to lock and unlock the mutex safely.
Functions like push() lock the mutex using std::lock_guard (an RAII wrapper that automatically
releases the lock when the scope ends), ensuring that the queue is modified in a thread‑safe manner. Once a new element
is pushed, cv.notify_one() is called to wake up a thread that may be waiting for data.
The wait_pop() function acquires the queue's mutex, pops if the queue is not empty. If the queue is
empty, the function does not return, but it wait for the cv to be notified, and then prompty checks if q is empty
(if it is a spurious wakeup). If q is not empty, it pops.
Why Condition Variables Instead of an Atomic Flag?
One might wonder why not simply use an atomic flag and a busy loop instead of a condition variable. The key reasons are:
- Busy Waiting Drawback: A thread continuously polling an atomic flag wastes CPU cycles, potentially leading to high CPU usage.
- Condition Variable Advantage: Condition variables allow threads to sleep (blocking at the kernel level) until an event—such as an item being pushed—occurs. This greatly reduces unnecessary CPU usage and allows the operating system to schedule other tasks efficiently.
- Handling Spurious Wakeups: The lambda predicate ensures that even if spurious wakeups occur, the thread only proceeds when the queue is truly not empty anymore.
Future Considerations: Fine‑Grained vs. Coarse‑Grained Locking
While my current design uses a coarse‑grained lock (one mutex for the entire queue), there are scenarios where you might consider fine‑grained locking—such as having one lock per index. However, this approach poses challenges:
False Sharing and Lock Placement: If locks are allocated contiguously (for example, stored in an array), adjacent locks could reside on the same cache line. When one thread acquires a lock, the cache line is updated and invalidated across cores. If another thread attempts to acquire an adjacent lock, it may experience a delay due to waiting for the updated cache line.
In contrast, a single coarse‑grained lock minimizes the number of lock objects, reducing the potential for false sharing but at the cost of serializing access to the entire queue.
Out‑of‑Order Execution and Branch Prediction
Out‑of‑Order Execution: Modern CPUs can rearrange independent instructions to maximize throughput. However, once a thread acquires the mutex, the critical section becomes serialized, which limits the benefits of out‑of‑order execution. That said, independent operations outside the locked region can still benefit from OoO execution.
Branch Prediction:
The code for lock acquisition (using std::lock_guard or std::unique_lock) involves
simple, highly predictable conditionals. Since the common case is that the lock is available, modern CPUs can
usually predict these branches efficiently, resulting in minimal overhead.
Overall, while the thread‑safe queue's single lock design serializes access, it provides a simple and reliable mechanism to ensure thread safety, minimizing CPU overhead and unnecessary busy waiting.
Thread Safe Singly Linked List
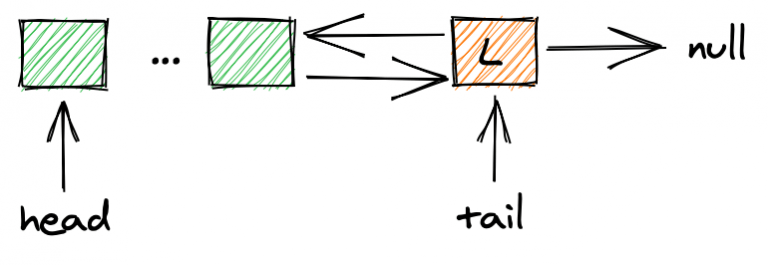
My thread safe singly linked list is designed to provide fine‑grained locking while ensuring robust memory management. To do this, each node in the list encapsulates its data and synchronization primitives. This design allows individual nodes to be locked independently, which is a different approach compared to the coarse‑grained lock used in my thread safe queue.
Node Structure
Each node in the linked list contains:
-
A
std::unique_ptr<T>for holding the value. This enforces exclusive ownership of the stored element. If I had used a raw pointer instead, the object might not be automatically deleted when the list goes out of scope. -
A
std::shared_ptr<Node>for the next pointer. This guarantees that nodes remain alive as long as there are references to them, simplifying memory management and preventing dangling pointers. -
A
mutable std::mutexfor fine‑grained locking. Declaring the mutex as mutable allows even const member functions (like anempty()check) to lock the mutex, ensuring safe access to shared data.
Linked List Pointers
To simplify boundary conditions, the linked list uses dummy (sentinel) nodes:
- dummy_head and dummy_tail serve as sentinel nodes, eliminating edge cases in insertion and deletion.
-
The pointer tail is maintained to support efficient
push_backoperations.
I chose smart pointers to manage both the value and the next pointer because they automatically handle memory deallocation when the list goes out of scope.
Locking Strategy
In order to allow concurrent modifications while maintaining data integrity, my design uses fine‑grained locking with one mutex per node:
- push_front: A
std::scoped_lockacquires the mutex fordummy_headand its next node simultaneously to prevent concurrent modifications at the front. - push_back: The operation locks the mutex of the current tail and the dummy tail before linking in a new node, protecting tail updates.
- remove_front: The mutexes for
dummy_headanddummy_head->nextare acquired to safely remove the first node.
Potential Deadlock Considerations:
Although std::scoped_lock helps by atomically locking multiple mutexes, care must be taken to:
- Maintain a consistent lock acquisition order across functions (e.g., locking (mutex1, then mutex2) in all relevant functions) to avoid circular waiting.
- Avoid trying to lock the same non‑recursive mutex twice, which would lead to a deadlock.
As a future enhancement, I plan to implement a thread‑safe doubly linked list, where the next pointer remains a shared pointer and the previous pointer is managed by a weak pointer to avoid circular references.
Cache Lines and False Sharing
In a linked list, each node is allocated separately (often via std::make_shared). Because these
nodes are not guaranteed to be contiguous, the embedded mutexes are less likely to reside on the same cache
line. This reduces the risk of false sharing, where multiple threads updating data on the same cache line cause
unnecessary cache invalidation.
Branch Prediction
My linked list operations include conditional checks—for example, verifying whether dummy_head->next equals dummy_tail to determine if the list is empty. These conditionals are typically highly predictable,
so modern CPUs efficiently predict these branches, resulting in minimal performance overhead.
Hashmap
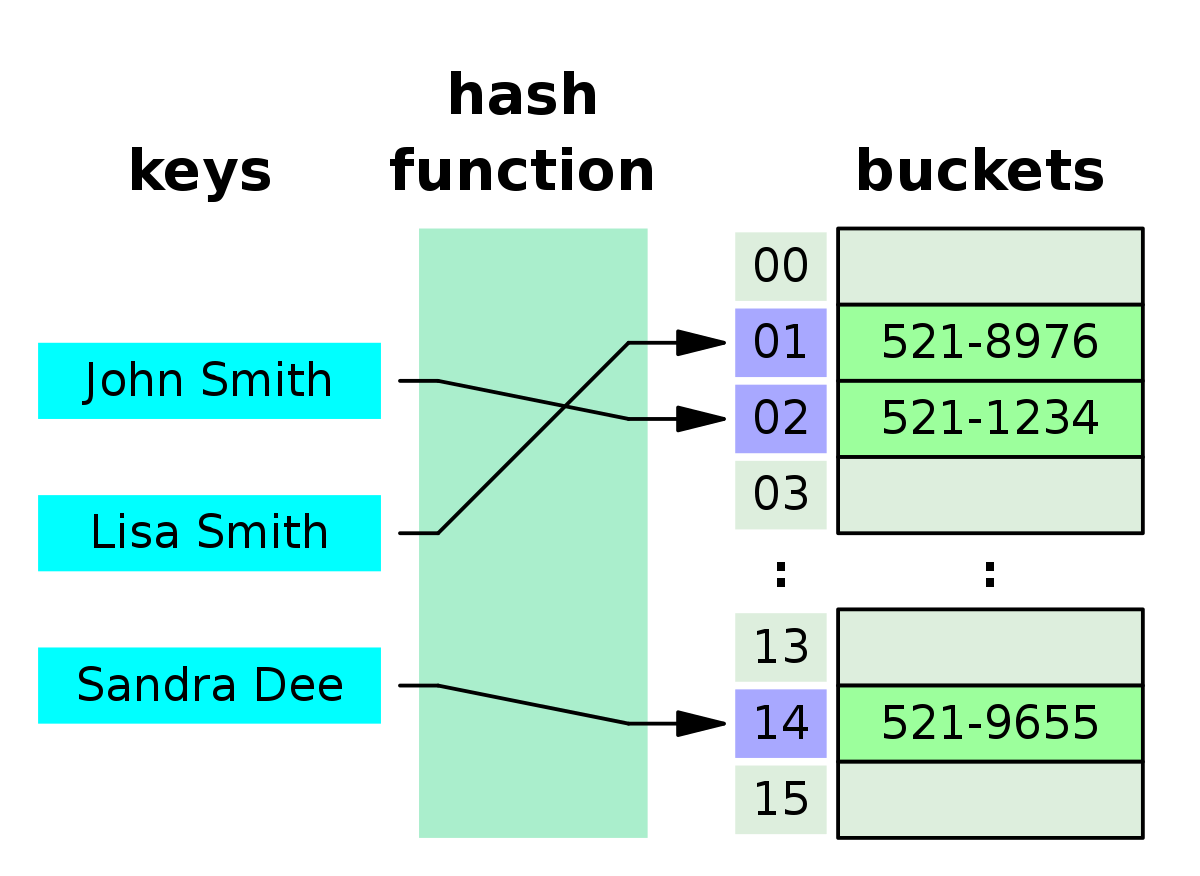
In my custom hashmap, collisions are resolved using separate chaining. I organize the data into an array of
buckets, where each bucket is a
std::list of key/value pairs (with type alias value_type defined as std::pair<const K, V>). This design provides:
- Flexibility: Each bucket maintains its own linked list, simplifying collision resolution.
- Simplicity: Using
std::listminimizes manual pointer management while offering fast insertion and deletion. - Having linked lists is a poor choice cache locality as they are not guaranteed to be contiguous in memory. However, having a good hash function that reduces collisions in the first place mitigates this. Using open addressing as a resolution mechanism, for example, could help to mitigate this.
Dynamic resizing is managed via a load factor threshold. I set maxLoadFactor to 0.7.
This load factor represents the ratio of elements to buckets at which performance begins to degrade, since
overly long chains cause lookups to slow down. When the ratio exceeds 0.7, the hashmap automatically rehashes,
increasing the bucket count and re-distributing elements. The value 0.7 is a common heuristic—it strikes a
balance between memory usage and lookup performance, ensuring a near‑constant average-time complexity for
insertions and lookups.
The bucket array (mStore) is allocated contiguously, which provides good cache locality during
bucket indexing. However, the individual nodes within each bucket—each element of the underlying std::list—are allocated separately on the heap. This means that while accessing a specific bucket is fast, iterating
over the linked list may incur more cache misses compared to a fully contiguous data structure. Fortunately,
with a good hash function, collisions will be minimal.
I made extensive use of type aliasing to simplify the code. For example:
using value_type = std::pair<const K, V>;
using Bucket = std::list<value_type>;
These aliases make the code cleaner and easier to maintain.
To allow users to iterate over all key/value pairs in the hashmap, I built a custom forward iterator that traverses bucket by bucket and then iterates within each bucket’s linked list.
Why Use std::move Instead of memcpy?
When rehashing, I use std::move for moving key/value pairs into the new buckets rather than memcpy. This is because key/value pairs may involve non‑trivial types that require proper invocation of move
constructors or destructors. std::move ensures that the elements’ state is transferred safely and their
resources are managed correctly, preserving proper object semantics.
My Design vs. STL’s unordered_map
Similarities:
-
Both my implementation and STL’s
unordered_mapuse separate chaining to resolve collisions. -
They support basic operations such as insertion, lookup (
find()andat()), deletion (erase()), and iteration. - A load factor threshold triggers rehashing, maintaining near‑constant average time for operations.
Differences:
- Allocators: STL’s
unordered_mapis allocator‑aware (parameterized with an allocator, likestd::allocator), allowing for more flexible and optimized memory management. My implementation uses raw dynamic allocation, which is simpler but less customizable. - Optimizations: STL’s implementation incorporates advanced optimizations, including node pooling and aggressive inlining, which have been refined over years of usage. My design is more straightforward and primarily serves as an educational example.
- Iterator Robustness: The iterators provided by STL offer strong guarantees regarding invalidation and are highly optimized for performance. My custom iterator is functional and provides similar basic traversal, but with fewer guarantees and optimizations.
Low‑Level Performance Considerations
Cache Lines and Memory Layout:
Since my bucket array (mStore) is allocated contiguously, accessing a specific bucket benefits from
spatial locality. However, because the nodes in each bucket’s linked list are dynamically allocated, traversing
a bucket may result in more cache misses. With a good hash function that distributes keys well, collisions are
reduced, and buckets are used more efficiently.
False Sharing: Although my hashmap isn’t initially designed for multi-threading, if extended for concurrent access false sharing might become an issue. If multiple threads update adjacent buckets (which are contiguous in memory), the cache line containing these buckets could become a contention point. STL libraries often mitigate this through padding or specialized allocators. A well‑distributed hash function helps spread bucket usage across memory, reducing the risk of false sharing.
Out‑of‑Order Execution: Operations like hashing and quickly iterating over short linked lists are independent, allowing modern CPUs to execute these instructions out‑of‑order. However, during rehashing, when many elements must be moved, the process becomes more sequential, limiting OoO benefits.
Branch Prediction: The control flow in my implementation—such as checking for empty buckets or determining whether to rehash—introduces some branches. Modern CPUs can predict these branches accurately, minimizing the latency impact of these conditionals.
String

In my custom String class, I implemented Small String Optimization (SSO) to efficiently handle common short strings—such as filenames, user inputs, and log messages—without incurring the overhead of dynamic memory allocation. The design uses a fixed‐size internal buffer of 128 bytes, which, being a multiple of 64, aligns well with common cache line sizes. This not only improves cache locality but also helps reduce false sharing in multi-threaded scenarios (my string implementation is not thread safe though).
Key Design Elements
- Internal Buffer (SSO):
For short strings (up to 128 characters), the data is stored directly within the object in a fixed-size buffer
(
smallBuffer). This avoids dynamic memory allocation for most common cases, leading to faster construction, copying, and destruction. - Dynamic Allocation for Long Strings: When a string exceeds 128 bytes (including null terminator), the data is allocated on the heap and managed accordingly.
Constructors and Appending Functions
The class provides several constructors:
- C-style String Constructor: Copies an input C-style string into the internal buffer.
- C-style String Constructor with Length: Constructs a string from a specific number of characters.
For appending, there are functions that accept either a C-style string or another custom String object. In both cases, the process involves:
- Allocating (or reusing) a temporary buffer,
- Copying the existing content,
- Appending the new content, and
- Updating the internal state.
This design ensures that short strings are managed efficiently, which is especially beneficial since small strings are extremely common in many applications.
Custom Iterator
I also implemented a custom bidirectional iterator for the String class, which supports both pre- and
post-increment/decrement operations. While my implementation uses a single iterator type with some casting to
handle both mutable and const access, a production version might provide separate iterator and const_iterator types for stronger const-correctness.
Clearing the String
To clear the string, I simply set the first element of the smallBuffer to the null terminator ('\0') and update the length to zero:
smallBuffer[0] = '\0';
len = 0;
Memory Layout: Where Is the SSO Stored?
The SSO buffer (smallBuffer) is declared as a fixed-size array within the String class:
char smallBuffer[SSO_SIZE + 1]; // SSO_SIZE is 128
Its exact location in memory depends on how the String object is allocated:
- Stack Allocation: If you create a String as a local variable, the entire object—including
smallBuffer—resides on the stack. - Heap Allocation: If the String object is dynamically allocated or stored in a container,
smallBufferis part of that heap allocation.
There's no need for manual deallocation of smallBuffer because it is managed automatically by the object's
lifetime.
Copy Assignment vs. Move Assignment
The copy assignment operator uses the copy‑and‑swap idiom to safely and efficiently transfer resources. Because
the SSO buffer is an array embedded in the object, it has a fixed memory location and cannot simply be swapped
by exchanging pointers (with std::swap). Instead, std::memcpy is used to swap the contents
of the small buffers, byte by byte. Casting it to an rvalue reference using std::move does not actually
copy over the contents—move semantics typically only exchange pointers, which doesn't make sense when the buffer
is embedded within the object.
In contrast, the move assignment operator transfers ownership of any heap‑allocated memory or, in the SSO case, copies the buffer contents from the source to the destination. The source is then reset to a valid empty state. Since we are "stealing" resources in a move, the swap idiom is unnecessary.
Performance Impact: Cache Lines, OoO Processing, and Branch Prediction
Cache Line Proximity: By setting the SSO threshold to 128 bytes—a multiple of 64—most short strings fit within one or two cache lines. This means that when the string is accessed, the entire string is likely to already be in cache, resulting in fewer cache misses.
Contiguous Storage and Memory Layout: Because the SSO buffer is embedded in the object, its data is stored contiguously with other member variables. This enhances spatial locality and reduces the chance of false sharing in a multi-threaded context, as each object's SSO buffer is isolated within its own memory allocation.
Out-of-Order Processing:
Functions like append() and string construction perform a minimal number of branches and independent
operations (such as checking the string length or copying data). Modern CPUs can execute these independent operations
out-of-order, which helps hide memory latency and improve overall throughput.
Branch Prediction: Most conditional checks in the string implementation (such as verifying whether the string fits within the SSO buffer or whether a pointer is null) are simple and predictable. As a result, modern CPUs accurately predict these branches, minimizing pipeline stalls. Uniform code paths—for example, centralizing append logic—help further by ensuring consistent branch behavior.